Table of Contents
This section gives a brief overview of the architechture used in BASE. This is a good starting point if you need to know how various parts of BASE are glued together. The figure below should display most of the importants parts in BASE. The following sections will briefly describe some parts of the figure and give you pointers for further reading if you are interested in the details.
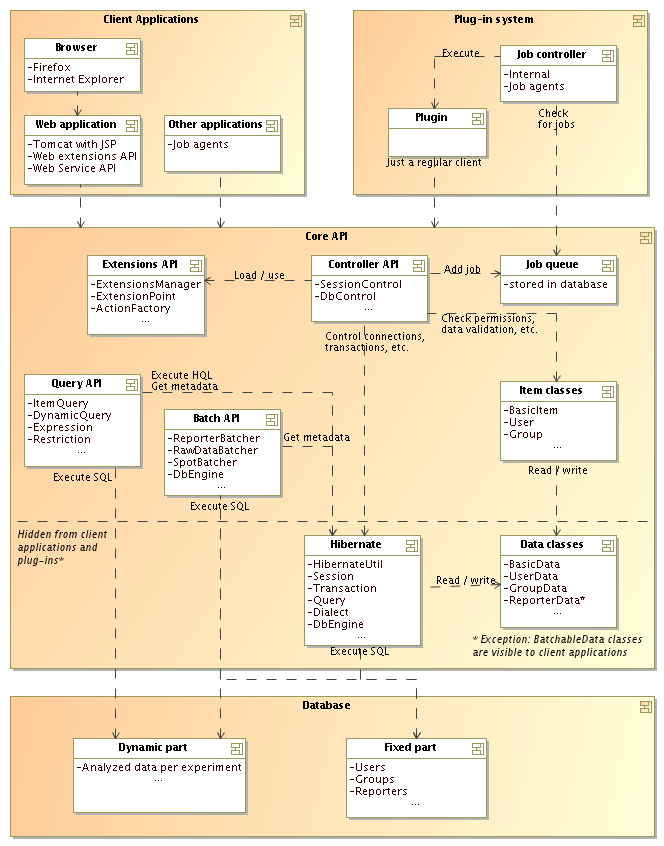
BASE stores most of it's data in a database. The database is divided into two parts, one fixed and one dynamic part.
The fixed part contains tables that corresponds
to the various items found in BASE. There is, for example, one table
for users, one table for groups and one table for reporters. Some items
share the same table. Biosources, samples and extracts are
all biomaterials and share the BioMaterials table. The access
to the fixed part of the database goes through Hibernate in most cases
or through the the Batch API in some cases (for example, access to reporters).
The dynamic part of the database contains tables for storing analyzed data. Each experiment has it's own set of tables and it is not possible to mix data from two experiments. The dynamic part of the database can only be accessed by the Batch API and the Query API using SQL and JDBC.
![[Note]](../gfx/admonitions/note.png) |
Note |
|---|---|
| The actual location of the two parts depends on the database that is used. MySQL uses two separate databases while PostgreSQL uses one database with two schemas. |
More information
Hibernate (www.hibernate.org) is an
object/relational mapping software package. It takes plain Java objects
and stores them in a database. All we have to do is to set the properties
on the objects (for example: user.setName("A name")). Hibernate
will take care of the SQL generation and database communication for us.
This is not a magic or automatic process. We have to provide mapping
information about what objects goes into which tables and what properties
goes into which columns, and other stuff like caching and proxy settings, etc.
This is done by annotating the code with Javadoc comments. The classes
that are mapped to the database are found in the net.sf.basedb.core.data
package, which is shown as the Data classes box in the image above.
The HibernateUtil class contains a
lot of functionality for interacting with Hibernate.
class contains a
lot of functionality for interacting with Hibernate.
Hibernate supports many different database systems. In theory, this means
that BASE should work with all those databases. However, in practice we have
found that this is not the case. For example, Oracle converts empty strings
to null values, which breaks some parts of our code that
expects non-null values. Another difficulty is that our Batch API and some parts of
the Query API:s generates native SQL as well. We try to use database dialect information
from Hibernate, but it is not always possible. The DbEngine contains code
for generating the SQL that Hibernate can't help us with. We have implemented
a generic DefaultDbEngine
which follows ANSI specifications and special drivers for MySQL
(MySQLEngine) and
PostgreSQL (PostgresDbEngine).
We don't expect BASE to work with other databases without modifications.
More information
Hibernate comes with a price. It affects performance and uses a lot of memory. This means that those parts of BASE that often handles lots of items at the same time doesn't work well with Hibernate. This is for example reporters, array design features and raw data. We have created the Batch API to solve these problems.
The Batch API uses JDBC and SQL directly against the database. However, we
still use metadata and database dialect information available from Hibernate
to generate most of the SQL we need. In theory, this should make the Batch API
just as database-independent as Hibernate is. In practice there is some information
that we can't extract from Hibernate so we have implemented a simple
DbEngine
to account for missing pieces. The Batch API can be used for any
BatchableData class in the
fixed part of the database and is the only way for adding data to the dynamic part.
|
Note |
|---|---|
| The main reason for the Batch API is to avoid the internal caching of Hibernate which eats lots of memory when handling thousands of items. Hibernate 3.1 introduced a new stateless API which among other things doesn't do any caching. This version was released after we had created the Batch API. We made a few tests to check if it would be better for us to switch back to Hibernate but found that it didn't perform as well as our own Batch API (it was about 2 times slower). In any case, we can never get Hibernate to work with the dynamic database, so the Batch API is needed. |
More information
The data classes are, with few exceptions, for internal use. These are the classes that are mapped to the database with Hibernate mapping files. They are very simple and contains no logic at all. They don't do any permission checks or any data validation.
Most of the data classes has a corresponding item class. For example:
UserData
and User,
GroupData and
Group.
The item classes are what the client applications can see and use. They contain
logic for permission checking (for example if the logged in user has WRITE permission)
and data validation (for example setting a required property to null).
The exception to the above scheme are the batchable classes, which are
all subclasses of the BatchableData
class. For example, there is a ReporterData
class but no corresponding item class. Instead there is a
batcher implementation, ReporterBatcher,
which takes care of the more or less the same things that an item class does,
but it also takes care of it's own SQL generation and JDBC calls that
bypasses Hibernate and the caching system.
More information
The Query API is used to build and execute queries against the data in the
database. It builds a query by using objects that represents certain
operations. For example, there is an EqRestriction object
which tests if two expressions are equal and there is an AddExpression
object which adds two expressions. In this way it is possible to build
very complex queries without using SQL or HQL.
The Query API knows how to work both via Hibernate and via SQL. In the first case it generates HQL (Hibernate Query Language) statements which Hibernate then translates into SQL. In the second case SQL is generated directly. In most cases HQL and SQL are identical, but not always. Some situations are solved by having the Query API generate slightly different query strings (with the help of information from Hibernate and the DbEngine). Some query elements can only be used with one of the query types.
|
Note |
|---|---|
The object-based approach makes it a bit difficult to store
a query for later reuse. The net.sf.basedb.util.jep
package contains an expression parser that can be used to convert
a string to Restriction:s and
Expression:s for
the Query API. While it doesn't cover 100% of the cases it should be
useful for the WHERE part of a query.
|
More information
The Controller API is the very heart of the BASE system. This part of the core is used for boring but essential details, such as user authentication, database connection management, transaction management, data validation, and more. We don't write more about this part here, but recommends reading the documents below.
More information
An extensions mechanism makes it possible to add functionality to BASE by external parties without having to modify the BASE code. This is not something that can be done at random, but BASE define a number of extension points which can been as a contract that must be fulfilled by the external code. Extension points are defined both by the BASE core (for example, file validators) and by the BASE web client (for example, menu and toolbar entries). In many cases, the distinction between an extension and a plug-in is fine. One major difference is that extensions are invoked and used immediately and are never queued for later execution. The installation mechanism is the same for both extensions and plug-ins and many packages use both types to provide a better user experience.
More information
From the core code's point of view a plug-in is just another client application. A plug-in doesn't have more powers and doesn't have access to some special API that allows it to do cool stuff that other clients can't.
However, the core must be able to control when and where a plug-in is
executed. Some plug-ins may take a long time doing their calculations
and may use a lot of memory. It would be bad if a several users started
to execute a resource-demanding plug-in at the same time. This problem is
solved by adding a job queue. Each plug-in that should be executed is
registered as Job in the database. A job controller is
checking the job queue at regular intervals. The job controller can then
choose if it should execute the plug-in or wait depending on the current
load on the server.
|
Note |
|---|---|
BASE ships with two types of job controllers. One internal that runs
inside the web application, and one external that is designed to run
on separate servers, so called job agents. The internal job controller
should work fine in most cases. The drawback with this controller is
that a badly written plug-in may crash the entire web server. For example,
a call to System.exit() in the plug-in code shuts down Tomcat
as well.
|
More information
Client applications are application that use the BASE Core API. The current web application is built with Java Server Pages (JSP). JSP is supported by several application servers but we have only tested it with Tomcat. Another client application is the external job agents that executes plug-ins on separate servers.
Although it is possible to develop a completely new client appliction from scratch we don't see this as a likely thing to happen. Instead, there are some other possibilites to access data in BASE and to extend the functionality in BASE.
The first possibility is to use the Web Service API. This allows you to access some of the data in the BASE database and download it for further use. The Web Service API is currently very limited but it is not hard to extend it to cover more use cases.
A second possibility is to use the Extension API. This allows a developer to add functionality that appears directly in the web interface. For example, additional menu items and toolbar buttons. This API is also easy to extend to cover more use cases.
More information
-
The BASE plug-ins site also has examples of extensions.