A Raw bioassay is the representation of the result of analyzing data from the physical bioassay down to the point where we have a file or a set of files containing measurements per feature (eg. spot, gene, etc.) for a single sample or extract. Further analysis is usually needed before we can say something about individual features or samples and how they relate to each other. This kind of analisys is done in Experiments. See Section 18.3, “Experiments”.
The term Raw bioassay is bit misleading since the real "raw data" is actually the images from a microarray scan or the output from a sequencer. For historical reasons we have chosen to keep the term raw bioassay since this represents the first possibility for a transition between file-base data and database-stored data. Typically, all pre-rawbioassay analysis is done outside of BASE, and although we now have the possibility to track this in detail, it will probably remain so for some time in the future. See Section 18.1, “Derived bioassays”.
Creating a new raw bioassay is a two- or three-step process:
-
Create a new raw bioassay item with the button in the raw bioassays list view. It is also possible to create raw bioassays from the derived bioassays list- and single view- page.
-
Upload the file(s) with the raw data and attach them to the raw bioassay.
-
The used platform may require that data is imported to the database. See Chapter 19, Import of data. If the platform is a file-only platform, this step can be skipped.
![[Note]](../../gfx/admonitions/note.png) |
Supported file formats |
|---|---|
| BASE has built-in support for most file formats where the data comes in a tab-separated (or similar) form. Data for one raw bioassay must be in a single file. Support for other file formats may be added through plug-ins. |
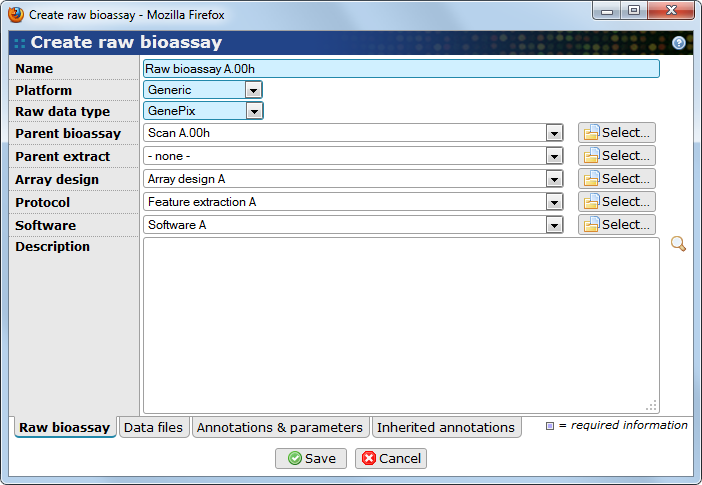
- Name
-
The name of the raw bioassay.
- Platform
-
Select the platform / variant used for the raw bioassay. The selected options affects which files that can be selected on the Data files tab. If the platform supports importing data to the database you must also select a Raw data type.
- Raw data type
-
The type of raw data. This option is disabled for file-only platforms and for platforms that are locked to a specific raw data type. This cannot be changed after raw data has been imported. See Section 18.2.4, “Raw data types”.
- Parent bioassay
-
The derived bioassay that is the parent of this raw bioassay.
- Parent extract
-
The extract which this raw bioassay has measured. This is normally selected among the extracts that are linked with the physical bioassay that this raw bioassay is coming from. Selecting the correct extract is important if the physical bioassay contains more than one extract, since otherwise it may affect how annotations are inherited and used in downstream analysis.
- Array design
-
The array design used on the array slide (optional). If an array design is specified the import will verify that the raw data has the same reporter on the same position. This prevents mistakes but also speed up analysis since some optimizations can be used when assigning positions in bioassay sets. The array design can be changed after raw data has been imported, but this triggers a new validation. If the raw data is stored in the database, the features on the new array design must match the the raw data. The verification can use three different methods:
-
Coordinates: Verify block, meta-grid, row and column coordinates.
-
Position: Verify the position number.
-
Feature ID: Verify the feature ID. This option can only be used if the raw bioassay is currently connected to an array design that has feature ID values already.
In all three cases it is also verified that the reporter of the raw data matches the reporter of the features.
For Affymetrix data, the CEL file is validated against the CDF file of the new array design. If the validation fails, the array design is not changed.
-
- Software
-
The software used to generate the raw data (optional).
- Protocol
-
The protocol used when generating the raw data (optional). Software parameters may be registered as part of the protocol.
- Description
-
A description of the raw bioassay (optional).
The Data files tab allows BASE users to select files that contains data for the raw bioassay. Read more about this in Section 11.4, “Selecting files for an item”.
The Annotations tab allows BASE users to use annotation types to refine bioassay description. More about annotating items can be read in Section 10.2, “Annotating items”
This Inherited annotations tab contains a list of those annotations that are inherited from the bioassay's parents. Information about working with inherited annotations can be found in Section 10.2.2, “Inheriting annotations from other items”.
Depending on the platform, raw data may have to be imported after you have created the raw bioassay item. This section doesn't apply to file-only platforms. The import is handled by plug-ins. To start the import click on the button on the single-item view for the raw bioassay. If this button does not appear it may be because no file format has been specified for the raw data type used by the raw bioassay or that the logged in user does not have permission to use the import plug-in or file format. See Chapter 19, Import of data for more information.
|
File-only platforms |
|---|---|
| File-only platforms, such as Affymetrix, is handled differently and data is not imported into the database. |
A raw data type defines the types of measured values that can be stored for individual features in the database. Usually this includes some kind of foreground and background intensity values. The number and meaning of the values usually depends on the hardware and software used to analyze the data from the experiment. Many tools provide mean and median values, standard deviations, quality control information, etc. Since there are so many existing tools with many different data file formats BASE uses a separate database table for each raw data type to store data. The raw data tables have been optimized for the type of raw data they can hold and only has the columns that are needed to store the data. BASE ships with a large number of pre-defined raw data types. An administrator may also define additional raw data type. See Appendix D, Platforms and raw-data-types.xml reference for more information.
In some cases it doesn't make sense to import any data into the database. The main reason is that performance will suffer as the number of entries in the database gets higher. A typical Genepix file contains ~55K spots while an Affymetrix file may have millions.
The drawback of keeping the data in files is that none of the generic tools in BASE can read it. Special plug-ins must be developed for each type of data file that can be used to analyze and visualize the data. For the Affymetrix platform there are implementations of the RMAExpress and Plier normalizations available on the BASE plug-ins web site. BASE also ships with built-in plug-ins for extracting metadata from Affymetrix CEL and CDF files (ie. headers, number of spots, etc).
Users of other file-only platforms should check the BASE plug-ins website for plug-ins related to their platform. If they can't find any we recommend that they try to find other users of the same platform and try to cooperate in developing the required tools and plug-ins.