
Opened 19 years ago
Closed 17 years ago
#294 closed enhancement (fixed)
Performance testing: Plugin-in execution time
| Reported by: | Johan Enell | Owned by: | Nicklas Nordborg |
|---|---|---|---|
| Priority: | blocker | Milestone: | BASE 2.5 |
| Component: | coreplugins | Version: | trunk |
| Keywords: | Cc: |
Description (last modified by )
The core plug-ins are slow. Just by running plug-ins on the demo server I've noticed that they are alot slower then the plug-ins from base1.
I've tested the intenisty calculator and Lowess but I think this affects every plug-in. Maybe some more tests should be done to locate if there is a bottleneck and it would be nice if we could create a best practice document.
See also #796 (Don't create indexes...) and #797 (Enhance performance for LOWESS...)
Attachments (4)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (21)
comment:1 by , 18 years ago
| Milestone: | BASE 2.x+ → BASE 2.1 |
|---|
comment:2 by , 18 years ago
| Owner: | changed from to |
|---|
comment:3 by , 18 years ago
| Milestone: | BASE 2.1 → BASE 2.2 |
|---|---|
| Summary: | Plugin-in execution time → Performance testing: Plugin-in execution time |
comment:4 by , 18 years ago
| Milestone: | BASE 2.2 → BASE 2.x+ |
|---|
comment:5 by , 18 years ago
| Milestone: | BASE 2.x+ → BASE 2.4 |
|---|
comment:6 by , 18 years ago
comment:8 by , 18 years ago
| Priority: | major → critical |
|---|
comment:9 by , 17 years ago
| Owner: | changed from to |
|---|---|
| Status: | new → assigned |
I will start to create a BASE 2 test framework that can be used to:
- Import reporters
- Create one array design
- Import a given number of raw bioassays from one or two data files
- Create an experiment and add the raw bioassays to it
- Create a root bioassayset from all raw bioassays
- Create a filtered bioassayset from the root bioassayset
- Normalize the filtered bioassayset with Lowess
Some parameters may be given on the command line that starts the test (for example the number of raw bioassays to create and which subtests to run). Some parameters may be given in a configuration file (for example parameters to the filter and lowess plug-ins).
I expect someone with more knowledge about BASE 1 and microarray analysis to help me with selecing proper parameter values, setting up a BASE 1 server for comparison, etc.
comment:10 by , 17 years ago
comment:11 by , 17 years ago
| Milestone: | BASE 2.4 → BASE 2.5 |
|---|
comment:12 by , 17 years ago
| Owner: | removed |
|---|---|
| Status: | assigned → new |
comment:13 by , 17 years ago
| Milestone: | BASE 2.5 → BASE 2.x+ |
|---|
comment:14 by , 17 years ago
| Description: | modified (diff) |
|---|---|
| Milestone: | BASE 2.x+ → BASE 2.5 |
| Owner: | set to |
| Priority: | critical → blocker |
| Status: | new → assigned |
Johan V-C has done some interesting test with the following plug-ins:
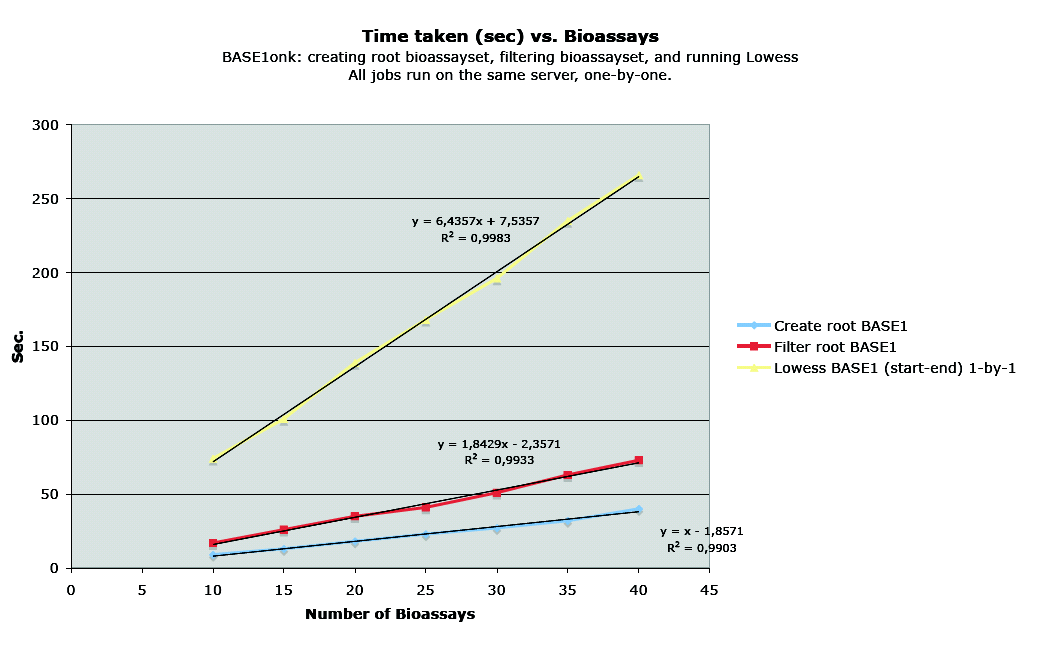
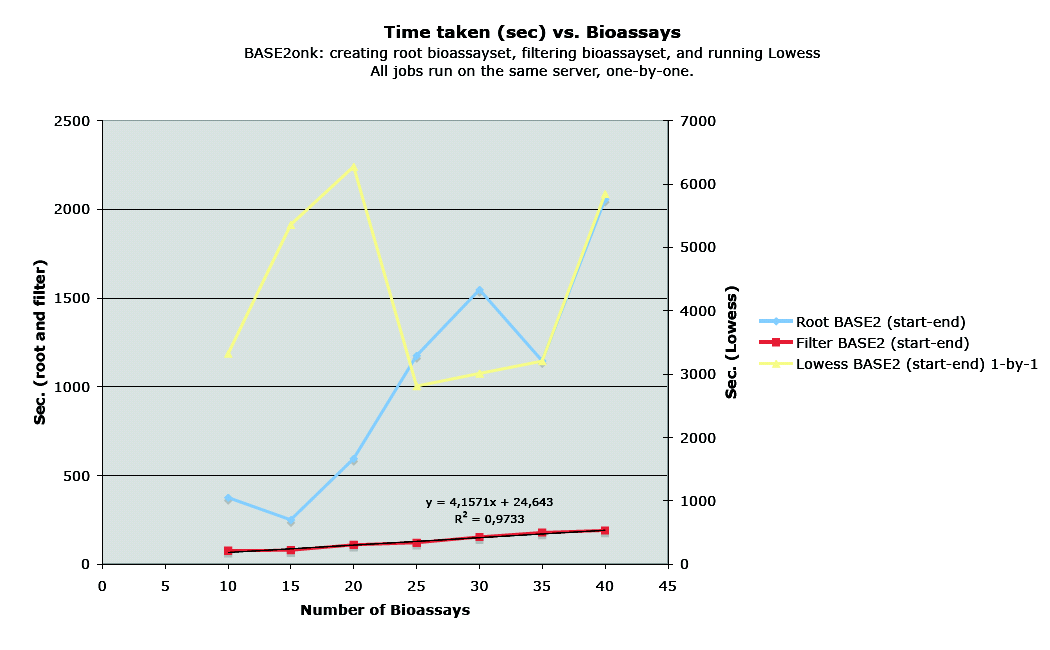
- Create root bioassayset. The same 55K raw data set has been used for 10-40 bioassays. Median FG - Median BG was used for intensity values
- Jep filter plugin: ch(1) > 0 && ch(2) > 0 && raw('flag') == 0
- Lowess plugin: step=0.1, window size=0.33, iterations=4, blockgroup size=1
Corresponding tests were done on the BASE 1 server. The results show that BASE 1 execution time is linear with respect to the number of bioassays. With BASE 2 only the filter plug-in is linear but takes about 3 times longer. The other plug-ins seems to have a random execution time that is 20-50 times longer than in BASE 1.
by , 17 years ago
| Attachment: | BASE1_prestanda_skalning.png added |
|---|
BASE 1 performance with respect to number of bioassays
by , 17 years ago
| Attachment: | BASE2_prestanda_skalning.png added |
|---|
BASE 2 performance with respect to number of bioassays
comment:15 by , 17 years ago
I made some tests at home and discovered the same pattern, but I also noticed that BASE 2 creates "extra" indexes on the same columns that make up the primary key for all tables in the dynamic database. When I removed the indexes the execution time for the filter plug-in dropped to about half and for the root bioassayset creation the time dropped to be equal to the time for the filter plug-in. The Lowess plug-in is faster, but not by much. I suspect that the problem here is that the number of issued SELECT SQL statements depends a lot on the 'blockgroup size' parameter. Descreasing the number of SELECT statements would make it a lot faster
by , 17 years ago
| Attachment: | perftest.txt added |
|---|
Test results when running with/without index on primary key columns
comment:16 by , 17 years ago
| Description: | modified (diff) |
|---|
comment:17 by , 17 years ago
| Resolution: | → fixed |
|---|---|
| Status: | assigned → closed |
Performance tuning for the whole application is also needed.