
Opened 9 years ago
Closed 9 years ago
#2006 closed enhancement (fixed)
Use parallel gzip implementation when compressing files
| Reported by: | Nicklas Nordborg | Owned by: | Nicklas Nordborg |
|---|---|---|---|
| Priority: | major | Milestone: | BASE 3.9 |
| Component: | core | Version: | |
| Keywords: | Cc: |
Description
Just found this: https://github.com/shevek/parallelgzip
Which seems interesting since we already know that pigz is a good performance booster: http://baseplugins.thep.lu.se/ticket/809#comment:5
I think we should try this out for the "Store compressed" option when saving files to the BASE file system. It may not improve things when loading files over the netweork, but there are cases when files are created locally.
The release export wizard developed for reggie (http://baseplugins.thep.lu.se/ticket/887) can generate files several GB in size. On my dev computer the throughput when storing compressed is 3Mb/s and 20Mb/s when storing uncompressed.
Attachments (1)
{kind=link}
Change History (12)
comment:1 by , 9 years ago
| Owner: | changed from to |
|---|---|
| Status: | new → assigned |
comment:2 by , 9 years ago
comment:3 by , 9 years ago
| Resolution: | → fixed |
|---|---|
| Status: | assigned → closed |
comment:5 by , 9 years ago
| Resolution: | fixed |
|---|---|
| Status: | closed → reopened |
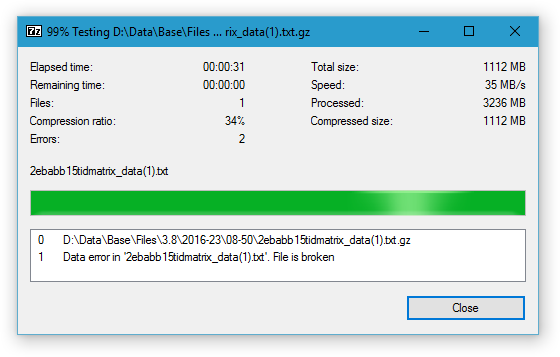
by , 9 years ago
| Attachment: | pgzip-test.png added |
|---|
Using 7z to test a file that was created with PGZip
comment:6 by , 9 years ago
Digging up the file from the internal BASE storage and testing it with 7z results in an error:

comment:7 by , 9 years ago
In theory it should be possible to handle the error while reading the file since we can compare the actual bytes that has been read with the known file size of the original file. Any errors that happens after that can be ignored. For example, wrapping the GZipInputStream with something like this seems to work:
@Override
public int read(byte[] buf, int start, int len)
throws IOException
{
try
{
return super.read(buf, start, len);
}
catch (EOFException ex)
{
if (inf.getBytesWritten() != getSize()) throw ex;
}
return -1;
}
However, personally I am not so happy about this solution which is more or less a "hack" for working around the problem with creating corrupt files to begin with. I think we should either abandon the PGZip implementation or try to fix the writing of the file.
comment:8 by , 9 years ago
(In [7170]) References #2006 and #2016.
Removed parallelgzip jar file and added source files to the BASE core package instead. The intention is to fix the file size problem. The current code is the original code as downloaded from https://github.com/shevek/parallelgzip (version 1.0.1). The code does not compile due to using non-standard annotation from "javax.annotation" package.
comment:9 by , 9 years ago
comment:10 by , 9 years ago
comment:11 by , 9 years ago
| Resolution: | → fixed |
|---|---|
| Status: | reopened → closed |
Tested the parallel implementation with the release exporter. Throughput is up to 8MB/s. Considering that the compressed file size is about 25% of the uncompressed this means that we are gaining time also over the uncompressed alternative.