Entering annotation values follow the same pattern for all items that can have annotations. They all have a Annotations & parameters tab in their edit view. On this tab you can specify values for all annotation types assigned to the type of item, and all parameters that are attached to the protocol used to create the item. Some items, for example biosources and array designs cannot have a protocol. In their case the tab is labelled Annotations.
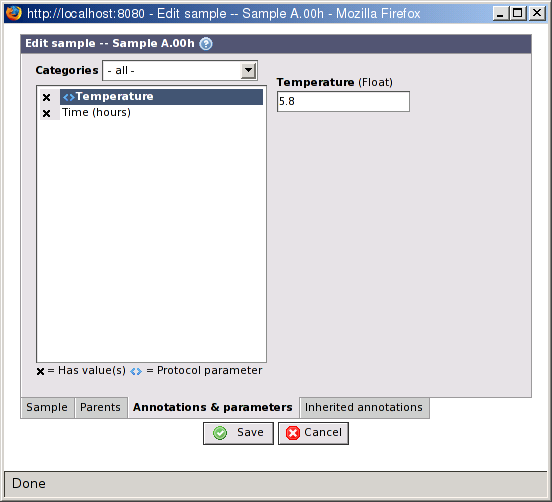
Click on an entry in the list of annotation types to show a form for entering a value for it to the right. Depending on the options set on the annotation type the form may be a simple free text field, a list of checkboxes or radiobuttons, or something else.
Annotation types with an X in front of their names already have a value.
Annotation types marked with angle brackets
(
 )
are protocol parameters.
)
are protocol parameters.
Select an option in the Categories list to filter the annotation types based on the categories they belong to. This list contains all available categories, and three special ones:
all: Display all annotation types
protocol parameters: Display only those annotation types that are parameters to the current protocol.
uncategorized: Display only annotation types that has not been put into a category.
An item may inherit annotations from any of it's parent items. E.g. an extract can inherit annotations from the sample or biosource it was created from. This is an important feature to make the experimental factors work. Annotations that should be used as experimental factors must be inherited to the raw bioassay level. See Section 18.3.2, “Experimental factors” for more information about experimental factors.
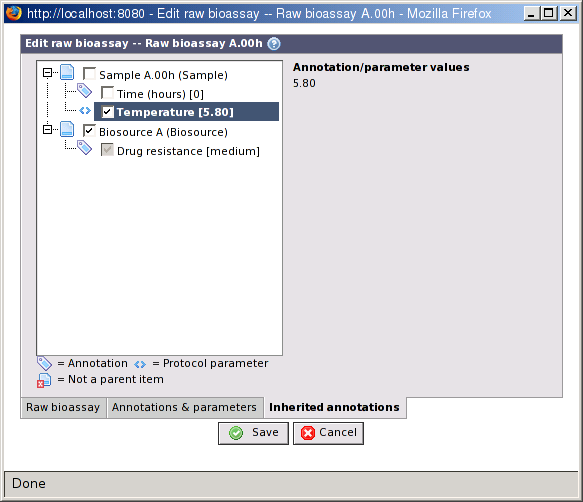
On this screen is a tree-like structure in two levels. The first level lists all parent items which has at least one annotations. The second level lists the annotations and protocol parameters for the item. Selecting an item in the first level will inherit all annotations from that item, including those that you maybe add later. Selecting an annotation or protocol parameter at the second level will inherit only the selected one.
![[Note]](../../gfx/admonitions/note.gif) |
Note |
|---|---|
|
![[Warning]](../../gfx/admonitions/warning.gif) |
Warning |
|---|---|
If you rearrange links to parent items after you have specified inheritance, it may happen that you are inheriting annotation from non-parent items. This will be flagged with a warning icon in the list, and must be fixed manually. The item overview tool is an excellent help for locating this kind of problems. See Section 6.6, “Item overview”. |
BASE includes a plug-in for importing annotations to multiple items in one go. The plug-in read annotation values from a simple column-based text file. Usually, a tab is used as the delimiter between columns. The first row should contain the column headers. One column should contain the name or the external ID of the item. The rest of the columns can each be mapped to an annotation type and contains the annotation values. If a column header exactly match the name of an annotation type, the plug-in will automatically create the mapping, otherwise you must do it manually. You don't have to map all columns if you don't want to.
Each column can only contain a single annotation value for each row. If you have annotation types that accept multiple values you can map two or more columns to the same annotation type, or you can add an extra row only giving the name and the extra annotation value. Here is a simple example of a valid file with comma as column separator:
# 'Time' and 'Age' are integer types # 'Subtype' is a string enumeration # 'Comment' is a text type that accept multiple values Name,Time (hours),Age (years),Subtype,Comment Sample #1,0,0,alfa,Very good Sample #2,24,0,beta,Not so bad Sample #2,,,,Yet another comment
The plug-in can be used with or without a configuration. The configuration keeps the regular expressions and other settings used to parse the file. If you often import annotations from the same file format, we recommend that you use a configuration. The mapping from file columns to annotation types is not part of the configuration, it must be done each time the plug-in is used.
The plug-in can be used from the list view of all annotatable items. Using the plug-in is a three-step wizard:
Select a file to import from and the regular expressions and other settings used to parse the file. In this step you also select the column that contains the name or external ID the items. If a configuration is used all settings on this page, except the file to import from, already has values.
The plug-in will start parsing the file until it finds the column headers. You are asked to select an annotation type for each column.
Set error handling options and some other import options.