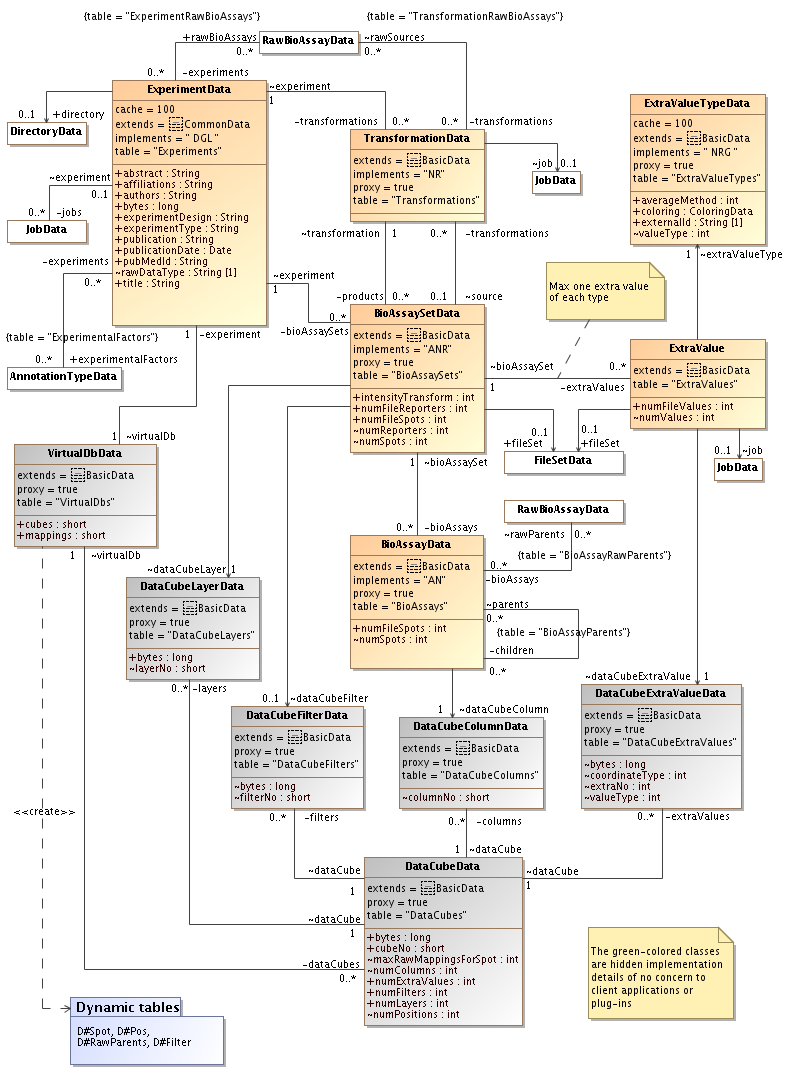
The ExperimentDataRawBioAssayDataRawDataType
Annotation types that are needed in the analysis must connected to the experiment as experimental factors and the annotation values should be set on or inherited by each raw bioassay that is part of the experiment.
The directory connected to the experiment is the default directory where plugins that generate files should store them.
Each line of analysis starts with the creation of a root
BioAssaySetDataBioAssayData
Information about the process that calculated the intensities are
stored in a TransformationDataJobData
Once the root bioassayset has been created it is possible to again apply a transformation to it. This time the transformation links to a single source bioassayset instead of the raw bioassays. As before, it still links to a job with information about the plug-in and parameters that does the actual work. The transformation must make sure that new bioassays are created and linked to the bioassays in the source bioassayset. This above process may be repeated as many times as needed.
Data to a bioassay set can only be added to it before it has been committed to the database. Once the transaction has been committed it is no longed possible to add more data or to modify existing data.
The above processes requires a flexible storage solution for the data.
Each experiment is related to a VirtualDb
A virual database is divided into data cubes. A data cube can be seen
as a three-dimensional object where each point can hold data that in
most cases can be interpreted as data for a single spot from an
array. The coordinates to a point is given by layer,
column and position. The
layer and column coordinates are represented by the
DataCubeLayerDataDataCubeColumnData
Data for a single bioassay set is always stored in a single layer. It
is possible for more than one bioassay set to use the same layer. This
usually happens for filtering transformations that doesn't modify the
data. The filtered bioassay set is then linked to a
DataCubeFilterData
All data for a bioassay is stored in a single column. Two bioassays in different bioassaysets (layers) can only have the same column if one is the parent of the other.
The position coordinate is tied to a reporter.
A child bioassay set may use the same data cube as it's parent bioassay set if all of the following conditions are true:
All positions are linked to the same reporter as the positions in the parent bioassay set.
All data points are linked to the same (possible many) raw data spots as the corresponding data points in the parent bioassay set.
The bioassays in the child bioassay set each have exactly one parent in the parent bioassay set. No parent bioassay may be the parent of more than one child bioassay.
If any of the above conditions are not true, a new data cube must be created for the child bioassay set.
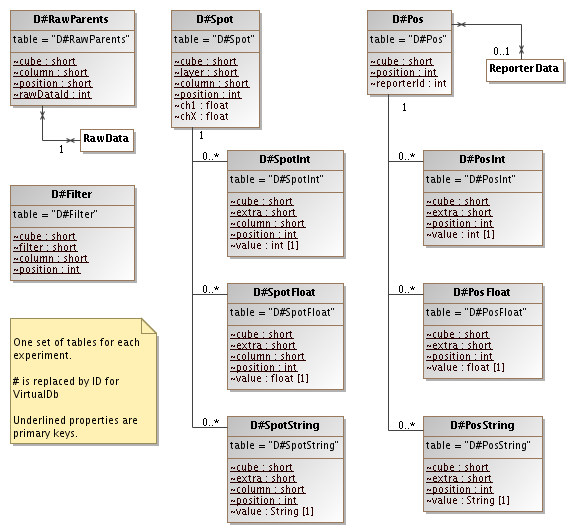
Each virtual database consists of several tables. The tables are dynamically created when needed. For each table shown in the diagram the # sign is replaced by the id of the virtual database object at run time.
There are no classes in the data layer for these tables and they are not mapped with Hibernate. When we work with these tables we are always using batcher classes and queries that works with integer, floats and strings.
The D#Spot table
This is the main table which keeps the intensities for a single spot in the data cube. Extra values attached to the spot are kept in separate tables, one for each type of value (D#SpotInt, D#SpotFloat and D#SpotString).
The D#Pos table
This table stores the reporter id for each position in a cube. Extra values attached to the position are kept in separate tables, one for each type of value (D#PosInt, D#PosFloat and D#PosString).
The D#Filter table
This table stores the coordinates for the spots that remain after filtering. Note that each filter is related to a bioassayset which gives the cube and layer values. Each row in the filter table then adds the column and position allowing us to find the spots in the D#Spot table.
The D#RawParents table
This table holds mappings for a spot to the raw data it is calculated from. We don't need the layer coordinate since all layers in a cube must have the same mapping to raw data.