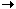 Initial technical specification
Initial technical specification
Initial technical specification
Initial technical specification
The current BASE 1.2 implementation uses a 3-tier architecure. At the bottom is the data layer running MySQL or Postgres. In the middle is the logic layer with PHP scripts running on an Apache web server. The top layer is the HTML presentation in the browser.
This follows a classical and well-known design for web applications. However, the actual implementation of it fails at several points, especially at the logic layer. Here are som exemples:
Several of the PHP scripts have too much responsibility. For example, the plotting function uses the script "plotter.inc.php". This script is responsible both for generating the HTML where the user selects parameters for the plot and for generating the final graphs in the form of images or postscript/pdf files.
Another example is the file "trans_create.phtml" which is used for filtering BioAssay data. It does the following:
There are too many dependencies between different parts of the PHP scripts and classes. This is actually the same problem as the first point but on a wider scale.
I will use the plot function as an example again. When the interface is presented for the user, he/she is supposed to select the values to plot on the X and Y axis respectively. The lists of values to choose from are generated by the BioAssay object. This is ok, since the BioAssay object is the only object that knows about what data is available. When the user has made the selection the information is passed to the BioAssay-object which fetches the data and gives it back to the plot function. This seems like a good idea, but if one looks deeper into the code there is a very tight coupling between the plot function an the BioAssay object. The BioAssay object has methods as "getDataForPlot" and "getPlotType", which are totally wrong. The BioAssay object should not need to know anything about plotting or how the data should be used. It should only have a "getData" method.
As it is now, the plot function will only plot data from a BioAssay, but what if we want to plot data from a BioAssaySet? The current design makes it hard to change the plot function to accomplish this.
SQL commands are scattered around in several different places. This will become a bigger problem as the code grows and the wish to support other databases increases. How do we verify that all SQL queries also work for example Oracle? And, once we have done that, what about the next version of BASE?
To summarize:
The basic problem is that the division into three layers has been unsuccessful.
Code that belongs to the data layer (SQL queries) are scattered among the script
in the logic layer. Several PHP scripts performs functions both for presenting
the data as well as manipulating it. Ie. there is no clear division between the
data layer, the logic layer and the presentation layer.
The main goal for BASE 2.0 is to make the division between data, logic and presentation clear.
Here are some features that are not requirements, but might be nice to have. We should try to include as much as possible, but if we are short of time some features may have to wait until a later version.
The generic solution is an extension to the current one, i.e. the 3-tier solution is replaced by an N-tier solution. This is accomplished by subdividing the layers and precisely specifying their areas of responsibility. At this stage we shouldn't make any assumption about the technology to use, i.e. the programming language, the kind of database, etc.
The data layer is divided into three layers:
The data abstraction layer is the only part of the data layer that is allowed to talk with the outside world, i.e. the logic layer, plugins, etc. Flaws in the actual design might make this impossible to follow at certain times, but much effort should go into not breaking this rule!
The logic layer is also divided into 3 parts:
Both the core and the plugins are allowed to talk to the data abstraction layer. Neither should talk to a specific database driver or use the data storage directly.
The helper classes should not talk to the core or the database layer. They should only depend on what they are fed from the presentation layer. It is arguable whether these components are seen as parts of the presentation layer or the logic layer. The reason I choose to put them in the logic layer is that they are providing services to several client applications.
The presentation layer is divided into 2 parts:
In addition to this the presentation layer can be extended with other client applications, i.e. standalone programs written in C++ or Perl or Java.
The presentation layer is only allowed to talk with the core layer and the helper classes. Communcation with plugins should go through the core layer.
The design could be represented by the following image:
......................................................................
Presentation layer
____________
| |
| Browser |
|____________|
|
| __________
_____v______ | |
| | | Other |
| Web server | | client |
|____________| |__________|
| | | |
...........|....|.............................|..|....................
| | ___________ | | Logic layer
| | | | | |
| ------>| Helper |<---------- |
| | classes | |
| |___________| |
| ____________________________|
| |
| _____v____ ___________
| | API | | |
____v__|__________|<--->| Plugins |
| | |___________|
| Core logic | |
| layer | |
|__________________| |<--Maybe
| |
..........|.........................|.................................
| ___________v____ Data layer
| | API |
___v_____________|________________|
| |
| Data abstraction layer |
| |
|----------------------------------|
| MySQL | |
| driver | Other drivers... |
|________|_________________________|
| |
| |
___v___ ____v_____
| | | |
| MySQL | | Other DB |
|_______| |__________|
............................................................
A visual representation of the system design
Note! In the image above the different layers do not correspond to the ability to break up the execution on different servers! A discussion about that will follow later.
Now we have a conceptual image of the design we are trying to accomplish. Until now we haven't paid much attention to the technincal details of the solution, i.e.:
The requirements specify that BASE must be able to use different data storage engines and that it should be possible to add support for other ones without major modification of the rest of the code.
The requirements does not specify what type of storage that should be supported, i.e. relational database, flat-file, xml, etc.
In order to not complicate the design we choose to limit the support to relational databases using SQL as the query language. The major task for a driver will then be to shield the rest of the application from the various dialects of SQL. The helper functions in the data abstraction layer will then most likely be ones that can be used for dynamic creation of SQL queries.
Other issues:
This is the ability to treat a series of SQL queries as one operation, i.e. if one query fails the rest would also fail and the database should be returned to the state prior to the beginning of the transaction.
In my opionion this is one of the most important features of a relational database. Nevertheless, we will not require that the database supports transactions. However, the code in the logic layer will assume that transactions are supported, if not directly in the database, then the data driver layer must handle upcoming issues with failing queries.
We will not require support for nested transactions. Neither at the storage or the driver level.
Requests for multi-language support will come sooner or later, and unicode is the way to go. As we will use Java as the programming language (see below) unicode support is already builtin at the code level. Again, we will not require unicode support by the data storage, but all code in the logic layer will behave as if it is supported. So, as for transactions, this is also an issue that the driver must take care of.
Opening a connection to a database is a timeconsuming operation. A connection pool maintains a list of already opened connections which can be recycled between different requests, thereby increasing the performance. With JDBC, it is not very complicated to add support for connection pooling for any database.
The requirements specify that this layer must expose an API usable for clients programmed in C++ and Perl, with optional support for Java.
It must also be able to handle plugins on both local and remote servers.
In the implementation of the core logic layer we will look at Java, since this is a well-designed language, which will make it easier to isolate and componentify functionality. In the database layer this will also give us automatic connection pooling through JDBC if the database supports it.
We will look at CORBA as the platform for the API. It will give us support for not only C++ and Perl, but also most other programming languages used today. Direct calling into the Java API is also allowed whenever that is more suitable. For instance, the web server should probably do that since going through CORBA every time migh affect performance. See also the discussion about scalability below.
More arguments:
The requirements says nothing about the presentation layer, but since BASE 1.2 is web-based it is implicit that we support a web interface for BASE 2.0.
The web server of choice is Apache. It has proven reliable and works on several platforms. The knowledge of how to setup and run an Apache web server is well spread.
We will use a scripting module on the web server. Java Server Pages is probably a good choice. It will certaily make it easy to use the core API. Perl is another possibility. There exists perl modules for using Java objects directly. The performance might suffer, but it is definitely worth to have a look at.
Other issues:
This is always an issue when designing web applications. Luckily the conformance with the different standards are getting better with each browser version. For this reason we should not support browsers that are too old at any price. Things to be considered are:
In my opinion there is no need to support older versions than IE 6.0 and NS 6.0. If we stay away from Dynamic HTML and similar technologies, any code that works on both of these browsers will probably work on most older ones also (IE 5.x and NS 4.x). Browser related issues can also easily be solved by the open source community.
Note! It is mainly an issue of testing, which takes a lot of time, and if one has to do it over and over again with different browser versions and operating systems it is going to take a lot of valuable time from more productive development.
The newer browsers support enough unicode to get it to work. Older ones have a few annoying issues (especially Netscape). See also the discussion about unicode for the data layer.
The scalability issue is only important in certain parts of the application. For instance, we do not expect the performance of the web server to be a problem. This is not the kind of application that attracts thousands or more simultaneous users.
On the other hand, some parts of the application can be very calculation intensive, i.e. the plugins. The requirements specify that it should be possible to run plugins on separate servers. With the use of CORBA this should not pose any problems. Differenent plugins can run on different servers and in theory it should be possible to create a cluster of servers for the plugins.
Because of the large quantities of data, the database itself may also be put under strain. It should not pose any problem to run the database on a different server. It is the database driver's responsibility to connect to the database and once connected it should not matter to the rest of the BASE application where it is located. One exception might be a low-level import and/or export function where the database reads/writes data from/to a file on the disk. In this case the network may have to be configured appropriately to allow the database to access the file or, if it is impossible, the driver should do the reading and writing, using SQL to communicate with the database.
The minimal configuration involves two computers:
The maximum configuration involves at least four computers:
Here is a list of what needs to be done before BASE 2.0 can be released. The list is ordered by the start time of each item. For a complete time plan see base2.0timplan.sxc.
BASE has a large user base and already a few interested developers. We need to notify them of our plans and find out if someone is interested in contributing to the development.
It is implicit that all functionality in the current version of BASE also should be in BASE 2.0. One important part of this specification is to specify plugins and import/export formats (implemented as plugins).
This specification should also include some use cases. A few of them will be used for the prototype development. All will be used during the main implementation and the testing.
The prototype should include test implementations of the most important technical problems we are expecting to encounter during the development.
At the end of the prototype development all decisions regarding technical solutions must have been made.
I don't think it is possible to create a version that is backwards compatible with BASE 1.2. This means that before the installation all data must be exported and then imported into the new version.
All points above includes writing documentation! Since it it a very important issue it is also included as a separate point. Proper documentation MUST be available for: