 Development information
Dynamic API overview
Inserting data
Development information
Dynamic API overview
Inserting data
Contents
This document contains an overview of the classes and methods used for inserting data into the dynamic tables.See also
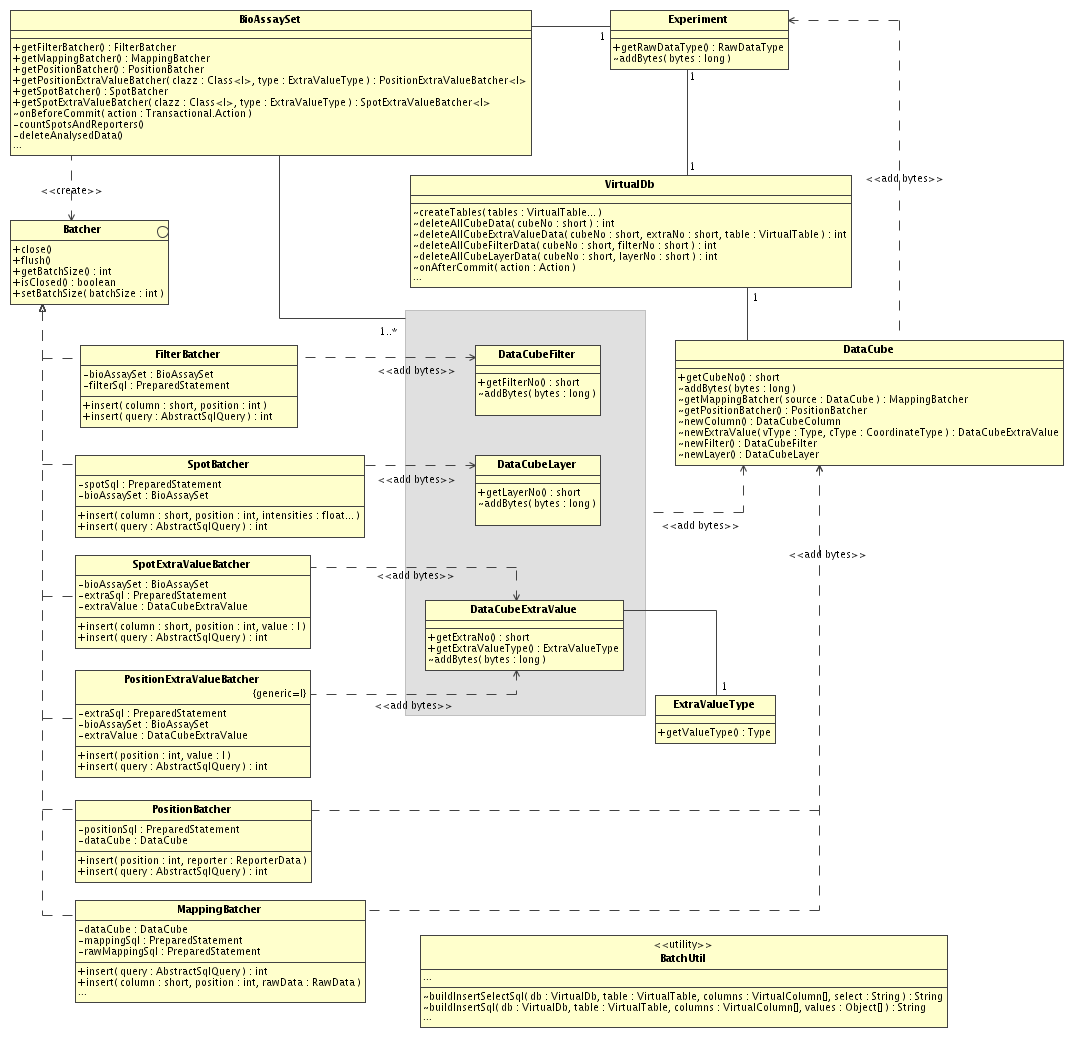
All data insertion is done with batcher classes. There are several different types
available, some that works on the data cube level and some that works on the
data cube layer level, ie. bioassayset. All batchers are created from a
BioAssaySet since this is the only object that is exposed (and of
interest) to client applications.
For a given data cube/bioassayset only one batcher of each type is can be created.
If any of the getXxxxBatcher() methods are invoked more than once the same
batcher will be returned. Once data has been committed the data cube / bioassayset
is marked as read-only. After that no batchers can be created to insert more
data.
All batchers keep track of the number of bytes the inserts are adding to the
database tables. When the batcher is closed it uses the addBytes
of the most relevant related item to update the disk usage. The call is always
propagated all the way up to the experiment, which collects the entire disk usage
and checks it against the owner's quota. But, we also need to store the disk usage
value at all intermediate levels (ie. data cube, layer, filter and extra value) since
it is possible to delete a single bioassayset at any time. Then we must know exactly how
many bytes that bioassayset contributed to the disk usage.
This is the central batcher which is used to insert intensities for each spot
in a bioassayset. When the batcher is created it uses BatchUtil to
create a PreparedStatement object used for inserting data into the
appropriate table.
INSERT INTO Dynamic#PerSpot (cube, layer, column, position, ch1, ch2) VALUES (<cube>, <layer>, ?, ?, ?, ?)
The real database table name is generated from the template by replacing
the # with the ID of the VirtualDb. This is done by the
VirtualTable object.
The <cube> and <layer> parameters are
fetched from the bioassayset and data cube the batcher is created from and statically
inserted into the SQL. Values for the other parameters are passed to the
insert method of the batcher.
Instead of inserting data for one spot at a time, it is possible to insert
a whole set of data in a single statement. This is done by the insert
methods that takes an AbstractSqlQuery as the only parameter. In this
case we do not use a prepared statement. Each call to insert generates
an SQL statement of the form INSERT INTO ... SELECT ... FROM ...
that takes the result of the query and inserts it.
// AbstractSqlQuery SELECT <select-columns> FROM <dynamic-query> // Insert query INSERT INTO Dynamic#PerSpot (cube, layer, column, position, ch1, ch2) SELECT <cube>, <layer>, <select-columns> FROM <dynamic-query>
Ie. we change the SELECT part of the query to also include
the static values for <cube> and <layer>.
The resulting query is then combined with an INSERT statement.
Note! This functionality requires that the original query selects the correct number of columns of the correct data type. This can't be validated by the core code, but we rely on the database for this.
Note! For string extra values this type of query doesn't work because we must
updated the disk usage information in the experiment. Numbers have a fixed length
so for float and int values we only have to check the number of rows the query
created. Strings have variable length. So, in this case we must execute the
query and then use the regular insert method
to insert one row at a time.
The other batchers are very similar to the spot batcher, and there is really not much more to say about them.