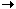 Development information
Dynamic API overview
Understanding the data cube
Development information
Dynamic API overview
Understanding the data cube
Contents
This document describes the data cube which is the central building block of the dynamic part of the database.See also
The data cube is a three-dimensional cube in which the coordinates layer,
column and position identifies a single spot. The small
dark blue box in the diagram indicates a single spot.
A spot is the main carrier of interesting data (intensities) and can be seen as a vector having a given number of intensity values and an arbitrary number of extra values. The number of intensity values in each spot is given by the number of channels in the raw data type used in an experiment. The intensity values are originally calculated from the information in the raw data associated with the experiment. Extra values are calculated by plugins using the intensities, raw data or other information.
The position coordinate is linked to a reporter. This means that all spots in a cube
with the same position coordinate (the light blue slice in the image) must have the same reporter.
The reporter may be null, and it is possible that two or more positions have the same reporter.
The position can also be linked to extra values. Just as for spots the values are calculated by plugins.
All extra values attached to a position are equally relevent to all spots having that position.
The layer coordinate is roughly equivalent to a bioassayset and the column
coordinate is roughly equivalent to a bioassay. However, it is possible that two or more bioassaysets
share the same layer. This happens whenever the spot data isn't changed by a transformation,
ie. a filter operation. If a transformation changes the spot data,
the new bioassayset must use a new layer. In the new bioassayset the new bioassays must
link one-to-one to the bioassays in the source bioassayset and they must use the same
column as the source bioassays are using.
The column coordinate is linked to one or more raw bioassays. This means that all spots in
a cube with the same column coordinate (the yellow slice in the image) must originate from the same set
of raw bioassays. Normally, a single column will just link to a single raw bioassay and two different columns
link to different raw bioassays. After a merge or other complex transformation this may change
and a new cube is needed.
All spots with the same combination of position and column (the green bar in the image)
coordinates are linked to the same set of raw data spots. Normally this means that all spots with the
same position/column values in the cube is linked to a single spot in a raw bioassay.
After a merge or other complex transformation there may be multiple links and a new
cube is needed.
If a transformation does some kind of merge, for example, merge all spots with the same reporter and take the mean of the intensities, or merge all spots with the same position in the different bioassays and take the mean of intensities, a new cube is needed. The transformation should also store information about how the merge was done, ie. for each spot in the new cube, the spots used from the parent cube should be stored. This is indicated by the arrows between the cubes in the image.