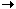 Development information
Coding rules and guidelines for the data layer
Development information
Coding rules and guidelines for the data layer
This document contains important information for the core Base developer. Most of this information is based on the "Hibernate in action" book and the Hibernate web site documentation. Sometimes our design choices do not follow the recommendations given in the book. In those cases we have clearly stated why we have chosen some other design.
When extending the database and creating new classes it is important that it follows the design of the already existing code. It is not very difficult or complicated.
Contents
See also
The coding guidelines for this package has been slightly modified from the the general coding guidelines. Here is a short list with the changes.
| Attributes and methods order |
Inside a class, attributes and methods should be organised
in related groups, ie. the private attribute is together
with the get and set methods that uses that attribute:
Example:
public static int long MAX_ADDRESS_LENGTH = 255;
private String address;
/**
@hibernate.property column="`address`" type="string" length="255" not-null="false"
*/
public String getAddress()
{
return address;
}
public void setAddress(String address)
{
this.address = address;
}
private int row;
/**
@hibernate.property column="`row`" type="int"
*/
public int getRow()
{
return row;
}
public void setRow(int row)
{
this.row = row;
}
|
| Class and interface names |
Class names should follow the general guidelines, but must end with Data.
Example:
public class SampleData
{
...
}
|
See the Data layer API overview - Basic classes and interfaces document.
For more information:
Each data-class must define a public a no-argument constructor. No other
constructors are needed. If we want to use other persistence mechanisms
or serializability in the future this type of constructor is probably
the most compatible. The constructor does not have to initialise properties
or create new internal objects. In fact, we recommend that it
doesn't do anything at all. Most of the time the object is
loaded by Hibernate and Hibernate will ensure that it is properly
initialised by calling all set methods.
For example, a many-to-many relation usually has a Set or a
Map to hold the links to the other objects. Do not create
a new HashSet or HashMap in the constructor.
Wait until the get method is called and only create a new
object if Hibernate hasn't already called the set method with
it's own object. See the code example below. There is also more information about
this in the "Mapping many-to-many and one-to-many" section below.
Our recommendation is that all constructors are empty, no-argument
constructors. Other objects are checked and initialised in the get
methods if necessary.
// GroupData.java
public GroupData()
{}
private Set<UserData> users;
public Set<UserData> getUsers()
{
if (users == null) users = new HashSet<UserData>();
return users;
}
For more information:
We use database identity to compare objects, ie. two objects are considered equal
if they are of the same class and have the same id, thus representing the same database
row. We may have some problems if we mix objects
which hasn't been saved to the database, with objects loaded
from the database. Our recommendation is to avoid that, and save any objects
to the database before adding them to sets, maps or any other structure
that uses the equals() and hashCode() methods.
To be more specific, the problem arises because of the two rules that the hash code
of an object mustn't change, and equal objects must have equal hash code.
For objects in the database, the hash code is based on the id. For new objects,
which doesn't have an id yet,
we fall back to the system hash code. But, what happens when we save the new
object to the database? If nobody has asked for the hash code it is safe to
use the id, otherwise we must stick with the system hash code. Now, imagine that
we load the same object from the database in another Hibernate session. What will now
happen? The loaded object will have it's hash code based on the id but the
original object is still using the system hash code, which most likely is
not the same as the id. Yet, the equals method returns true. This is a violation of the contract for
the equals method. If these two objects are used in a set it may cause
unexpected behaviour. Therefore, do not put new objects in a set, or other
collection, that calls the hashCode() method before the object is saved to
the database.
All this stuff is implemented by the BasicData class.
Therefore it is required that all classes are subclasses of this class. It is
recommended that the equals() or hashCode()
methods are not overridden by any of the subclasses. We would have liked to
make them final, but then the proxy feature of Hibernate would not work.
final methodsFor more information:
No methods should be tagged with the final keyword. This is a
requirement to be able to use the proxy feature of Hibernate, which we need for
performance reasons.
For more information:
To gain performance we use the second-level cache of Hibernate. It
is a transparent feature that doesn't affect the code in any way.
The second-level cache is configured in the hibernate.cfg.xml
and ehcache.xml files and not in the individual class mapping files.
BASE is shipped with a standard configuration,
but different deployment scenarios may have to fine-tune the cache settings
for that particular hardware/software setup. It is beyond the scope of this
document to discuss this (advanced) issue.
The second-level cache is suitable for objects that are rarely modified
but are needed often. For example, we do not expect the user information
represented by the UserData object to change
very often, but it is displayed all the time as the owner of various items.
It is required that one thinks a bit of the usage of a class before coming up with a good caching strategy. We have to answer the following questions:
The first question is the most important. Good candidates are classes
with few objects that change rarely, but are read often. Also, objects which are linked
to by many other objects are good candidates. The UserData
class is an example which matches all three requirements.
The LabelData class is an example which fulfils the first two.
The BioMaterialEventData class is on the other hand a bad cache
candidate, since it is not linked to any other object than a
BioMaterialData object.
The answer to the second question depends on how often an object is modified. For most objects this time is probably several days or months, but we would not gain much by keeping objects in the cache for so long. Suddenly, the information has changed and we won't risk that old information is kept that long. We have set the timeout to 1 hour for all classes so far, and we don't recommend a longer timeout. The only exception is for immutable objects, that cannot be changed at all, which may have an infinite timeout.
The answer to the third question depends a lot on the hardware (available memory). With lots of memory we can afford to cache more objects. Caching to disk is not really necessary if the database is on the same machine as the web server, but if it is on another machine we have to consider the network delay to connect to the database versus the disk access time. The default configuration does not use disk cache.
For more information:
Proxies are also used to gain performance, and they may have some impact
on the code. Proxies are created at runtime as a subclass of the
actual class and are not populated with data until some method of the object
is called. The data is loaded from the database the first time a method
other than getId() is called. Thus, we can avoid loading data
that is not needed at a particular time.
There can be a problem with using the instanceof operator with proxies
and the table-per-class-hierarchy mapping. For example, if we have the abstract
class Animal and subclasses Cat and Dog.
The proxy of an Animal is a runtime generated subclass of
Animal, since we do not know if it is a Cat
or Dog. So, x instanceof Dog and x instanceof Cat
would both return false. If we hadn't used a proxy, at least one of them would
always be true.
Proxies are only used when a not-null object is linked with many-to-one or one-to-one from another object. If we ask for a specific object by id, or by a query, we will never get a proxy. Therefore, it only makes sense to enable proxies for classes that can be linked from other classes. One-to-one links on the primary key where null is allowed silently disables the proxy feature, since Hibernate doesn't know if there is an object or not without querying the database. Ie. The linked object is always loaded.
The goal of a proxy and the second-level cache are the same: to avoid hitting the database. It is perfectly possible to enable both proxies and the cache for a class. Then we would start with a proxy and as soon as a method is called Hibernate would look in the second-level cache. Only if it is not there it would be loaded from the database. But, do we really need a proxy in the first place? Well, I think it might be better to use only the cache or only proxies. But, this also makes it even more important that the cache is configured correctly so there is a high probability that the object is already in the cache.
If a class has been configured to use the second-level cache, we recommend that proxies are disabled. For child objects in a parent-child relationship proxies should be disabled, since they have no other links to them than from the parent. If a class can be linked as many-to-one from several other classes it makes sense to enable proxies. If we have a long chain of many-to-one relations it may also make sense to enable proxies at some level, even if the second-level cache is used. In that case we only need to create one proxy instead of looking up several objects in the cache. Also, think about how a particular class most commonly will be used in a client application. For example, it is very common to display the name of the owner of an item, but we are probably not interested in displaying quota information for that user. So, it makes sense to put users in the second-level cache and use proxies for quota information.
Starting with Hibernate 3.1 there is a new stateless session feature. A stateless session has no first-level cache and doesn't use the second-level cache either. This means that if we load an item with a stateless session Hibernate will always traverse many-to-one and one-to-one associations and load those objects as well, unless they are configured to use proxies.
Stateless sessions are used by batchable items (reporters, raw data and features) since they are many and we want to use as little memory as possible. Here it is required that proxies are enabled for all items that are linked from any of the batchable items, ie. RawBioAssay, ReporterType, ArrayDesignBlock, etc.
On the other hand, the proxies created from a stateless session cannot later be initialised. We have to get the ID from the proxy and the load the object using the regular session. This also means that a batchable class shouldn't use proxies.
Here is a table which summarises different settings for the second-level cache, proxies, batch fetching and many-to-one links. Batch fetching and many-to-one links are discussed later in this document.
First, decide if the second-level cache should be enabled or not. Then, if proxies should be enabled or not. The table then gives a reasonable setting for the batch size and many-to-one mappings. NOTE! The many-to-one mappings are the links from other classes to this one, not links from this class.
The settings in this table are not absolute rules. In some cases there might be a good reason for another combination. Please, write a comment about why the recommendations were not followed.
| Global configuration | Class mapping | Many-to-one mapping | |
|---|---|---|---|
| Cache | Proxy | Batch-size | Outer-join |
| no | no* | yes | true |
| yes | no* | no | false |
| no | yes | yes | false |
| yes | yes | no | false |
The AnyData.txt and
ChildData.txt files contains two complete
data classes with lots of template methods. Please copy and paste as much
as you want from these, but do not forget to change everything to what you actually need.
For more information:
Example:
/**
This class holds information about any data
@author Your name
@version 2.0
@hibernate.class table="`Anys`" lazy="false" batch-size="10"
@base.modified $Date: 2009-04-06 14:52:39 +0200 (mĂĄ, 06 apr 2009) $
*/
public class AnyData
extends CommonData
{
// Rest of class code...
}
The class declaration must contain a Javadoc entry (@hibernate.class)
where Hibernate can find the name of the table where items of this type are stored.
The table name should generally be the same as the class name, without the ending
Data and in a plural form. For example UserData -->
Users. The back-ticks (`) around the table name tells Hibernate to enclose the name in
whatever the actual database manager uses for such things (back-ticks in MySQL,
quotes for an ANSI-compatible database).
The lazy attribute enables/disables proxies for the class. Do not
forget to specify this attribute since the default value is true.
If proxies are enabled, it may also make sense to specify a batch-size
attribute. Then Hibernate will load the specified number of items in each SELECT statement
instead of loading them one by one. It may also make sense to specify a
batch size when proxies are disabled, but then it would probably be even better
to use eager fetching by setting outer-join="true"
(see many-to-one mapping).
Classes that are linked with a many-to-one association from a batchable class
must specify lazy="true". Otherwise the stateless session feature
of Hibernate may result in a large number of SELECT:s for the
same item, or even circular loops if two or more items references each other.
hibernate.cfg.xml
and ehcache.xml.
For more information:
The column names should generally be the same as the get/set method name without the get/set prefix, and with upper-case letters converted to lower-case and an underscore inserted. Examples:
getAddress() --> column="`address`"
getLoginComment() --> column="`login_comment`"
The back-ticks (`) around the column name tells Hibernate to enclose the name in whatever the actual database manager uses for such things (back-ticks in MySQL, quotes for an ANSI-compatible database).
public static int long MAX_STRINGPROPERTY_LENGTH = 255;
private String stringProperty;
/**
Get the string property.
@hibernate.property column="`string_property`" type="string"
length="255" not-null="true"
*/
public String getStringProperty()
{
return stringProperty;
}
public void setStringProperty(String stringProperty)
{
this.stringProperty = stringProperty;
}
Do not use a greater value than 255 for the length attribute. Some
databases has that as the maximum length for character columns (ie. MySQL). If you need
to store longer texts use type="text" instead. You can then
skip the length attribute. Most databases will allow up to
65535 characters or more in a text field. Do not forget to specify the
not-null attribute.
You should also define a public constant MAX_STRINGPROPERTY_LENGTH
containing the maximum allowed length of the string.
private int intProperty;
/**
Get the int property.
@hibernate.property column="`int_property`" type="int" not-null="true"
*/
public int getIntProperty()
{
return intProperty;
}
public void setIntProperty(int intProperty)
{
this.intProperty = intProperty;
}
It is also possible to use Integer, Long or
Float objects instead of int, long and
float. We have only used it if null values have some meaning.
private boolean booleanProperty;
/**
Get the boolean property.
@hibernate.property column="`boolean_property`"
type="boolean" not-null="true"
*/
public boolean isBooleanProperty()
{
return booleanProperty;
}
public void setBooleanProperty(boolean booleanProperty)
{
this.booleanProperty = booleanProperty;
}
It is also possible to use a Boolean
object instead of boolean. We have not used
it, and it is only required if you absolutely need null values.
private Date dateProperty;
/**
Get the date property. Null is allowed.
@hibernate.property column="`date_property`" type="date" not-null="false"
*/
public Date getDateProperty()
{
return dateProperty;
}
public void setDateProperty(Date dateProperty)
{
this.dateProperty = dateProperty;
}
Hibernate defines several other date and time types. We have decided to use
the type="date" type when we are only interested in the date and
the type="timestamp" when we are interested in both the date and time.
For more information:
Example:

private OtherData other;
/**
Get the other object.
@hibernate.many-to-one column="`other_id`" not-null="true" outer-join="false"
*/
public OtherData getOther()
{
return other;
}
public void setOther(OtherData other)
{
this.other = other;
}
We create a many-to-one mapping with the @hibernate.many-to-one tag.
The most important attribute is the column attribute which specifies
the name of the database column to use for the id of the other item. The
back-ticks (`) around the column name tells Hibernate to enclose the name in whatever
the actual database manager uses for such things (back-ticks in MySQL, quotes for an
ANSI-compatible database).
We also recommend that the not-null attribute is specified.
Hibernate will not check for null values, but it will generate table columns
that allow or disallow null values. See it as en extra safety feature while debugging.
It is also used to determine if Hibernate uses LEFT JOIN or
INNER JOIN in SQL statements.
The outer-join attribute is important and affects how the cache and
proxies are used. It can take three values: auto, true
or false. If the value is true Hibernate will always
use a join to load the linked object in a single select statement, overriding the cache
and proxy. This value should only be used if the class being linked has disabled both
proxies and the second-level cache, or if it is a link between a child and parent in
a parent-child relationship. A false value
is best when we expect the associated object to be in the second-level cache
or proxying is enabled. This is probably the most common case.
The auto setting
uses a join if proxying is disabled otherwise it uses a proxy. Since we always know
if proxying is enabled or not, this setting is not very useful. See the table in the section
about proxies above for the recommended settings.
For more information:
There are many variants of mapping many-to-many or one-to-many, and
it is not possible to give examples of all of them. In the code these
mappings are represented by Set:s, Map:s,
List:s, or some other collection object.
The most important thing to remember is that (in our application) the collections are only
used to maintain the links between objects. They are not used for returning
objects to client applications, as is the case with the many-to-one
mapping.
For example, if we want to find all members of a group
we do not use the GroupData.getUsers() method, instead we
will execute a HQL statement to retrieve them. The reason for this design is that the
logged in user may not have access to all users and we must add a permission
checking filter to the HQL. It will also allow client applications to
specify sorting and filtering options for the users that are returned.
Example:

// RoleData.java
private Set<UserData>;
/**
Many-to-many from roles to users
@hibernate.set table="`UserRoles`" lazy="true"
@hibernate.collection-key column="`role_id`"
@hibernate.collection-many-to-many column="`user_id`"
class="net.sf.basedb.core.data.UserData"
*/
public Set<UserData> getUsers()
{
if (users == null) users = new HashSet<UserData>();
return users;
}
void setUsers(Set<UserData> users)
{
this.users = users;
}
As you can see this mapping is a lot more complicated than what we have seen
before. The most important thing is the lazy attribute. It tells Hibernate
to delay the loading of the related objects until the set is accessed. If the
value is false or missing, Hibernate will load all objects immediately.
There is almost never a good reason to specify something other than
lazy="true".
Another important thing to remember is that the get method
must always return the same object that Hibernate passed to the set
method. Otherwise, Hibernate will not be able to detect changes made to the
collection and as a result will have to delete and then recreate all links.
We have made the setUsers() method package private, and the
getUsers() will create a new HashSet for us
if Hibernate didn't pass one in the first place.
// UserData.java
private Set<RoleData> roles;
/**
Many-to-many from users to roles
@hibernate.set table="`UserRoles`" lazy="true"
@hibernate.collection-key column="`user_id`"
@hibernate.collection-many-to-many column="`role_id`"
class="net.sf.basedb.core.data.RoleData"
*/
Set<RoleData> getRoles()
{
return roles;
}
void setRoles(Set<RoleData> roles)
{
this.roles = roles;
}
The only real difference here is that both methods are package private.
This is required because Hibernate will get confused if we modify both ends.
Thus, we are forced to always add/remove users to/from the set in the
GroupData object. Note that we do not have to check for null and
create a new set since Hibernate will handle null values as an empty set.
inverse="true" setting
that can be used with the @hibernate.set tag, that will
ignore changes made to that collection. However, there is one problem
with specifying this attribute. Hibernate doesn't delete entries in
the association table, leading to foreign key violations if we try to
delete a user. The only solutions are to skip the inverse="true"
attribute or to manually delete the object from all collections on
the non-inverse end. The first alternative is the most efficient since it
only requires a single SQL statement, the second must first load all
associated objects and then issue a single delete statement for each
association.
In the "Hibernate in action" book they have a very different design where they recommend that changes are made in both collections. We don't have to do this since we are only interested in maintaining the links, which is always done in one of the collections.
So, why do we need the second collection at all? It is never accessed except by Hibernate, and since it is lazy it will always be "empty". The answer is that we want to use the relation in HQL statements. For example:
SELECT ... FROM GroupData grp WHERE grp.users ... SELECT ... FROM UserData usr WHERE usr.groups ...
Without the inverse mapping, it would not have been possible to execute the second HQL statement. The inverse mapping is also important in parent-child relationships, where it is used to cascade delete the children if a parent is deleted.
// AnyData.java
private Set<ChildData> children;
/**
One-to-many between parent and children.
@hibernate.set lazy="true" inverse="true" cascade="delete"
@hibernate.collection-key column="`parent_id`"
@hibernate.collection-one-to-many class="net.sf.basedb.core.data.ChildData"
*/
Set<ChildData> getChildren()
{
return children;
}
void setChildren(Set<ChildData> children)
{
this.children = children;
}
// ChildData.java
private AnyData parent;
/**
Get the parent.
@hibernate.many-to-one column="`parent_id`" not-null="true" update="false"
*/
public AnyData getParent()
{
return parent;
}
public void setParent(AnyData parent)
{
this.parent = parent;
}
This show both sides of the one-to-many mapping between parent and children.
As you can see the hibernate.set doesn't specify a table, since
it is given by the class attribute of the
hibernate.collection-one-to-many tag. The cascade
attribute is discussed in the "Parent-child relationships" section below.
In a one-to-many mapping, it is always the "one" side that handles the link so the "many" side should always be mapped as inverse and the collections need never be modified.
Here is a map from project to user with the user's permission int the
project as the map value. Note that the inverse end is mapped as a
set instead of a map.

// ProjectData.java
private Map<UserData,Integer> users;
/**
Many-to-many mapping between projects and users including permission values.
@hibernate.map table="`UserProjects`" lazy="true"
@hibernate.collection-key column="`project_id`"
@hibernate.index-many-to-many column="`user_id`"
class="net.sf.basedb.core.data.UserData"
@hibernate.collection-element column="`permission`" type="int" not-null="true"
*/
public Map<UserData,Integer> getUsers()
{
if (users == null) users = new HashMap<UserData,Integer>();
return users;
}
void setUsers(Map<UserData,Integer> users)
{
this.users = users;
}
// UserData.java
private Set<ProjectData> projects;
/**
This is the inverse end.
@see ProjectData#getUsers()
@hibernate.set table="`UserProjects`" lazy="true"
@hibernate.collection-key column="`user_id`"
@hibernate.collection-many-to-many column="`project_id`"
class="net.sf.basedb.core.data.ProjectData"
*/
Set<ProjectData> getProjects()
{
return projects;
}
void setProjects(Set<ProjectData> projects)
{
this.projects = projects;
}
For more examples of sets, maps, lists, etc. see "Hibernate in action" or the online documentation at http://www.hibernate.org
For more information:
A one-to-one mapping can come in two different forms, depending on if the mapped objects should have the same id or not. We start with the case were the objects can have different id:s and the link is done with an extra column in one of the tables. The example is from the mapping between hybridizations and arrayslides.

// HybridizationData.java
private ArraySlideData arrayslide;
/**
Get the array slide
@hibernate.many-to-one column="`arrayslide_id`" not-null="false" unique="true"
*/
public ArraySlideData getArraySlide()
{
return arrayslide;
}
public void setArraySlide(ArraySlideData arrayslide)
{
arrayslide.setHybridization(this);
this.arrayslide = arrayslide;
}
// ArraySlideData.java
private HybridizationData hybridization;
/**
Get the hybridization
@hibernate.one-to-one property-ref="arraySlide"
*/
public HybridizationData getHybridization()
{
return hybridization;
}
void setHybridization(HybridizationData hybridization)
{
this.hybridization = hybridization;
}
As you can see, we use the many-to-one mapping on
with a unique="true" option for the hybridization. This
will force the database to only allow the same array slide to be linked
once.
For the array slide end we use a one-to-one mapping
and specify the name of the property on the other end that we are
linking to. Also, note that the we can only change the link with the
HybridizationData.setArraySlide() method, and that this method
also updates the other end.
The second form of a one-to-one mapping is used when both objects must have the same id. The example is from the mapping between users and passwords.

// UserData.java
/**
@hibernate.id column="`id`" generator-class="foreign"
@hibernate.generator-param name="property" value="password"
*/
public int getId()
{
return super.getId();
}
private PasswordData password;
/**
Get the password.
@hibernate.one-to-one class="net.sf.basedb.core.data.PasswordData"
cascade="all" outer-join="false" constrained="true"
*/
public PasswordData getPassword()
{
if (password == null)
{
password = new PasswordData();
password.setUser(this);
}
return password;
}
void setPassword(PasswordData user)
{
this.password = password;
}
We start with the mapping from the user to the password. Again, we
use the one-to-one mapping and specify the class we
link to. The constrained="true" tells Hibernate to
always insert the password first, and then the user. The reason
for this is that the (auto-generated) id for the password also becomes
the id for the user. This is controlled by the mapping for the
getId() method, which uses the foreign
id generator. This generator will look at the password
property, ie. call getPassword().getId() to find the
id for the user.
Here is the inverse link from password to user:
// PasswordData.java
private UserData user;
/**
Get the user.
@hibernate.one-to-one class="net.sf.basedb.core.data.UserData"
*/
public UserData getUser()
{
return user;
}
void setUser(UserData user)
{
this.user = user;
}
For more information:
When one or more objects are tightly linked to some other object
we talk about a parent-child relationship. This kind of relationship
becomes important when we are about to delete a parent object.
The children cannot exist without the parent so they must also
be deleted. Luckily, Hibernate can do this for us if we specify
a cascade="delete" option for the link. This example
is a one-to-many link between client and help texts.
// ClientData.java
private Set<HelpData> helpTexts;
/**
This is the inverse end.
@see HelpData#getClient()
@hibernate.set lazy="true" inverse="true" cascade="delete"
@hibernate.collection-key column="`client_id`"
@hibernate.collection-one-to-many class="net.sf.basedb.core.data.HelpData"
*/
Set<HelpData> getHelpTexts()
{
return helpTexts;
}
void setHelpTexts(Set<HelpData> helpTexts)
{
this.helpTexts = helpTexts;
}
// HelpData.java
private ClientData client;
/**
Get the client for this help text.
@hibernate.many-to-one column="`client_id`" not-null="true"
update="false" outer-join="false" unique-key="uniquehelp"
*/
public ClientData getClient()
{
return client;
}
public void setClient(ClientData client)
{
this.client = client;
}
The cascade option can be given to almost any
link, although it makes most sense for one-to-many or many-to-many
links.
The cascade option can also be used to save and update
objects, but we feel that it is better to have control over such things.
Documenting the code consists of two parts:
The first type of documentation is not very difficult to write, although it may be a bit boring. We have made a few rules.
The documentation for the class doesn't have to be very lengthy. A single sentence is
usually enough. Provide tags for the author, version, last modification date and a reference
to the corresponding class in the net.sf.basedb.core package
and to the overview documentation for the section the class belongs to.
Example:
/**
This class holds information about any items.
@author Your name
@version 2.0
@see net.sf.basedb.core.AnyItem
@see <a href="../../../../../../development/overview/data/anyitem.html">Any
item overview</a>
@base.modified $Date: 2009-04-06 14:52:39 +0200 (mĂĄ, 06 apr 2009) $
@hibernate.class table="`Anys`" lazy="false"
*/
public class AnyData
extends CommonData
{
...
}
Write a one-sentence description for all public get methods. You do not
have document the parameters or the set methods, since it would just be a repetition.
Methods defined by interfaces are documented in the interface class. You should
not have to write any documentation for those methods.
For the inverse end of a link, which has only package private methods, write a notice about this and provide a link to to non-inverse end. Examples:
// UserData.java
private String address;
/**
Get the address for the user.
@hibernate.property column="`address`" type="string" length="255"
*/
public String getAddress()
{
return address;
}
public void setAddress(String address)
{
this.address = address;
}
private Set<GroupData> groups;
/**
This is the inverse end.
@see GroupData#getUsers()
@hibernate.set table="`UserGroups`" lazy="true" inverse="true"
@hibernate.collection-key column="`user_id`"
@hibernate.collection-many-to-many column="`group_id`"
class="net.sf.basedb.core.data.GroupData"
*/
Set<GroupData> getGroups()
{
return groups;
}
void setGroups(Set<GroupData> groups)
{
this.groups = groups;
}
Write a short one-sentence description for public static final
fields. Private fields does not have to be documented. Example:
/** The maximum length of the name of an item that can be stored in the database. @see #setName(String) */ public static int MAX_NAME_LENGTH = 255;
Documenting how this class is related to other classes is a more difficult task. Generally it involves drawing a UML-like diagram. This type of documentation is not done on a per-class basis but in chunks of related classes. For example we group together users, groups, roles, etc. into an authentication class diagram. It is also possible that a single class may appear in more than one diagram.
To create the diagrams we use a program called MagicDraw. A demo version can be downloaded from their web site: http://www.magicdraw.com/
We have tried to keep the diagrams compact, but still containing as much information as possible. For a class we need information about:
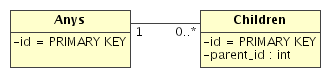
We have used the functionality to attach "Tagged values" to a class in MagicDraw for all but the last two items in the list above. To define tagged values you double-click on a class. In the dialog that opens switch to the "Tagged values" tab. Use the "Add" button to add a tag and enter a value for it in the right part of the dialog box.
table tag.
cache
tag if caching is enabled. Otherwise, skip this tag.
proxy tag if proxies are enabled, otherwise
skip this tag.
extends
tag.
implements tagged value. The value
is a string of letters each one corresponding to a single interface:
public
get and set methods.
public get and set methods and an update="false"
tag in the Hibernate mapping.
public get and set methods for many-to-one associations.
Many-to-many associations have a public get method but a package private
set method for reasons described above.
update="false" tag in the Hibernate mapping should be
used. For many-to-many association there is no corresponding tag.
It will be the responsibility of the core to make sure no
modifications are done.
If the association involves an extra table (many-to-many) the name of that table should be entered as the name of the association.
If the association have values attached to it, use a third class and then attach it to the association with the "Link attribute" link. A lot more can be said about this, but it is probably better to have a look at already existing diagrams if you have any questions. The authentication overview shown below is one of the most complex diagrams that involves many different links.
