BASE 2.5 introduced the possibility to use files to store data instead
of importing it into the database. Files can be attached
to any item that implements the FileStoreEnabledRawBioAssayArrayDesign
Data in files only
Data in the database only
Data in both files and in the database
Not all three cases are supported for all types of data. This is controlled
by the PlatformPlatform.isFileOnly() and/or
Platform.getRawDataType(). If the isFileOnly()
method returns true, the platform can't store data in
the database. If the value is false more information
can be obtained by calling getRawDataType(),
which may return:
null: The platform can store data with any raw data type in the database.A
RawDataTypethat has isStoredInDb() == true: The platform can store data in the database but only data with the specified raw data type.A
RawDataTypethat has isStoredInDb() == false: The platform can't store data in the database.
One major change from earlier BASE versions is that the registration of raw data types
has changed. The raw-data-types.xml file should
only be used for raw data types that are stored in the database. The
storage tag has been deprecated and BASE will refuse
to start if it finds a raw data type definitions with storage="file".
For backwards compatibility reasons, each Platformfalse
from the RawDataType.isStoredInDb()
method. They also have a back-link to the platform/variant that
created it: RawDataType.getPlatform()
and RawDataType.getVariant(). These two methods
will always return null when called on a raw data type
that can be stored in the database.
See also
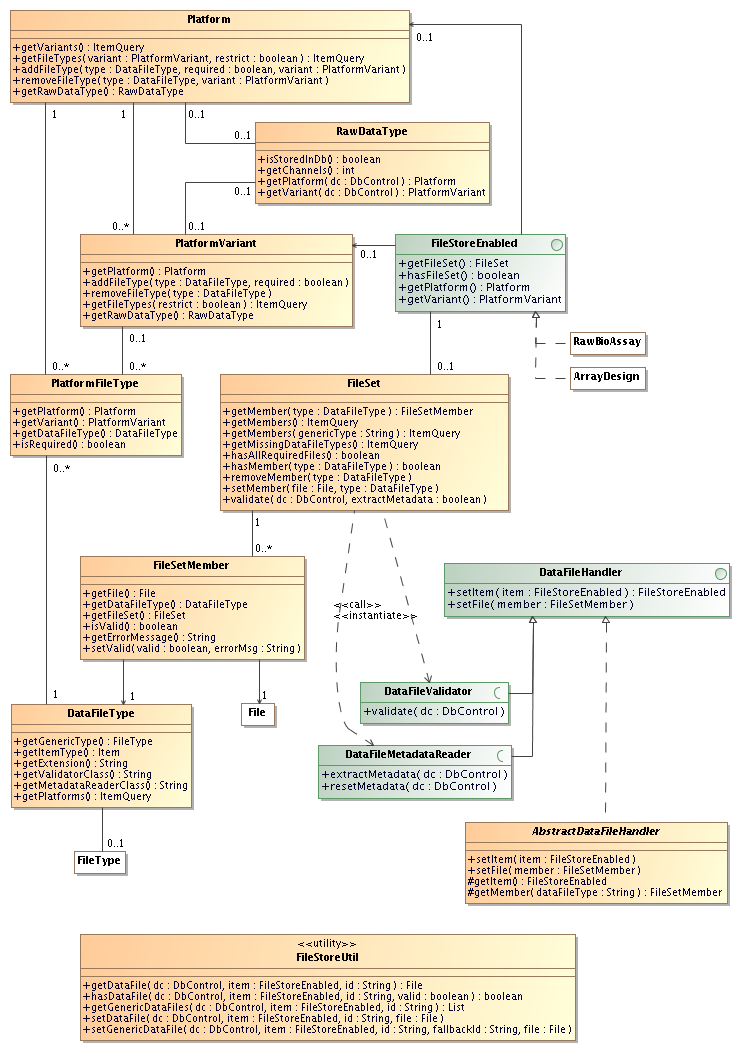
This is rather large set of classes and methods. The ultimate goal
is to be able to create links between a RawBioAssayArrayDesignFileFileStoreUtil
A client application must know what types of files it makes sense to ask the user for. In some cases, data may be split into more than one file so we need a generic way to select files.
Given that we have a FileStoreEnabledDataFileTypeDataFileType.getQuery(FileStoreEnabled)
can be used for this. Internally, the method uses the result from
FileStoreEnabled.getPlatform()
and FileStoreEnabled.getVariant()
methods to restrict the query to only return file types for
a given platform and/or variant. If the item doesn't have
a platform or variant the query will return all file types
that are associated with the given item type. In any case, we get a list
of DataFileType items, each one representing a
specific file type that we should ask the user about. Examples:
The
Affymetrixplatform definesCELas a raw data file andCDFas an array design (reporter map) file. If we have aRawBioAssaythe query will only return the CEL file type and the client can ask the user for a CEL file. The
Genericplatform definesPRINT_MAPandREPORTER_MAPfor array designs. If we have anArrayDesignthe query will return those two items.
It might also be interesting to know the currently selected file
for each file type and if the platform has set the required
flag for a particular file type. Here is a simple code example
that may be useful to start from:
DbControl dc = ...
FileStoreEnabled item = ...
Platform platform = item.getPlatform();
PlatformVariant variant = item.getVariant();
// Get list of DataFileTypes used by the platform
ItemQuery<DataFileType> query =
DataFileType.getQuery(item);
List<DataFileType> types = query.list(dc);
// Always check hasFileSet() method first to avoid
// creating the file set if it doesn't exists
FileSet fileSet = item.hasFileSet() ?
null : item.getFileSet();
for (DataFileType type : types)
{
// Get the current file, if any
FileSetMember member = fileSet == null || !fileSet.hasMember(type) ?
null : fileSet.getMember(type);
File current = member == null ?
null : member.getFile();
// Check if a file is required by the platform
PlatformFileType pft = platform == null ?
null : platform.getFileType(type, variant);
boolean isRequired = pft == null ?
false : pft.isRequired();
// Now we can do something with this information to
// let the user select a file ...
}
![[Note]](../../gfx/admonitions/note.gif) |
Also remember to catch PermissionDeniedException |
|---|---|
The above code may look complicated, but this is mostly because
of all checks for |
When the user has selected the file(s) we must store the links
to them in the database. This is done with a FileSetFileSet.setMember() to store
a file in the file set. If a file already exists for the given file type
it is replaced, otherwise a new entry is created. The following
program example assumes that we have a map where FileDataFileTypeFileSet.validate()
to validate the files and extract metadata.
DbControl dc = ...
FileStoreEnabled item = ...
Map<DataFileType, File> files = ...
// Store the selected files in the fileset
FileSet fileSet = item.getFileSet();
for (Map.Entry<DataFileType, File> entry : files)
{
DataFileType type = entry.getKey();
File file = entry.getValue();
fileSet.setMember(type, file);
}
// Validate the files and extract metadata
fileSet.validate(dc, true);
Validation and extraction of metadata is important since we want
data in files to be equivalent to data in the database. The validation
and metadata extraction is done by the core when the
FileSet.validate() is called.
The process is partly pluggable since each DataFileType
|
Note |
|---|---|
The |
Here is the general outline of what is going on in the core:
The core checks the
DataFileTypeof all members in the file set and creates DataFileValidatorand DataFileMetadataReaderobjects. Only one instance of each class is created. If the file set contains members which has the same validator or metadata reader, they will all share the same instance. Each validator/metadata reader class is initialised with calls to
DataFileHandler.setItem()andDataFileHandler.setFile().Each validator is called. The result of the validation is saved for each file and can be retreieved by
FileSetMember.isValid()andFileSetMember.getErrorMessage().Each metadata reader is called, unless the metadata reader is the same class as the validator and the validation failed. If the metadata reader is a different class, it is called even if the validation failed.
|
Only one instance of each validator class is created |
|---|---|
The validation/metadata extraction is not done until all files have been
added to the fileset. If the same validator/meta data reader is
used for more than one file, the same instance is reused. Ie.
the |
All validators and meta data extractors should extend
the AbstractDataFileHandlerDataFileHandlerAbstractDataFileHandler
This should be done by existing plug-ins in the same way as before.
A slight modification is needed since it is good if the importers
are made aware of already selected files in the FileSetFileStoreUtil
RawBioAssay rba = ... DbControl dc = ... // Get the current raw data file, if any List<File> rawDataFiles = FileStoreUtil.getGenericDataFiles(dc, rba, FileType.RAW_DATA); File defaultFile = rawDataFiles.size() > 0 ? rawDataFiles.get(0) : null; // Create parameter asking for input file - use current as default PluginParameter<File> fileParameter = new PluginParameter<File>( "file", "Raw data file", "The file that contains the raw data that you want to import", new FileParameterType(defaultFile, true, 1) );
An import plug-in should also save the file that was used to the file set:
RawBioassay rba = ...
// The file the user selected to import from
File rawDataFile = (File)job.getValue("file");
// Save the file to the fileset. The method will check which file
// type the platform uses as the raw data type. As a fallback the
// GENERIC_RAW_DATA type is used
FileStoreUtil.setGenericDataFile(dc, rba, FileType.RAW_DATA,
DataFileType.GENERIC_RAW_DATA, rawDataFile);
Just as before, an experiment is still locked to a single
RawDataTypePlatform
A plug-in (using data from the database that needs to check if it can be used within an experiment can still do:
Experiment e = ...
RawDataType rdt = e.getRawDataType();
if (rdt.isStoredInDb())
{
// Check number of channels, etc...
// ... run plug-in code ...
}
A newer plug-in which uses data from files should do:
Experiment e = ...
DbControl dc = ...
RawDataType rdt = e.getRawDataType();
if (!rdt.isStoredInDb())
{
// Check that platform/variant is supported
Platform p = rdt.getPlatform(dc);
PlatformVariant v = rdt.getVariant(dc);
// ...
// Get data files
File aFile = FileStoreUtil.getDataFile(dc, ...);
// ... run plug-in code ...
}